| DeepSeek 이어 Moonshot까지, 中 LLM 경쟁 ‘불꽃’ | ||
|
||
|
□ 2025년 7월 11일, 중국 LLM 기업 Moonshot AI(月之暗面)*가 공개한 오픈소스 모델 Kimi K2는 출시 직후 높은 활용성과 성능을 바탕으로 글로벌 기술 생태계의 주목을 받고 있음(25.7.15)
* Moonshot AI는 2023년 4월 베이징에서 설립된 민간 LLM 스타트업으로, 칭화대 출신 신진연구자 중심의 기술 조직과 생성형 AI 개발에 주력하고 있음
○ (출시) Moonshot AI의 오픈소스 모델 Kimi K2는 출시 단 이틀 만에 OpenRouter 플랫폼에서 토큰 사용량 기준 1.5% 점유율을 기록하며, xAI(1.2%)를 추월함
* OpenRouter는 OpenAI, Google 등 약 400여 개 LLM 모델의 API를 통합 제공하는 플랫폼이며, ‘토큰 사용량’은 모델 호출 시 소비된 총 토큰 수를 기준으로 산정됨. 이는 AI 모델의 실제 사용 빈도와 개발자 선호도를 반영하는 주요 지표임
○ (성능) Kimi K2는 코딩, 도구 활용, 수학·STEM 분야에서 GPT-4, Claude 3.5, DeepSeek 등 유력 모델과 비교해 전반적으로 가장 높은 성능을 보였으며, 오픈소스 모델임에도 상용 모델 수준의 기술력을 입증함
 ○ (비용) Kimi K2는 LiveCodeBench 기준(LLM의 실질적 코딩 성능 평가 기준) 53.7점으로 최고의 코딩 성능을 기록했고, API 요금도 입력 $0.60, 출력 $2.50로 가장 저렴함
* Claude 4 Sonnet은 48.5점, GPT-4.1은 44.7점을 기록했으며, API 요금은 각각 $3.00/$15.00, $2.00/$8.00로 상대적으로 고가임
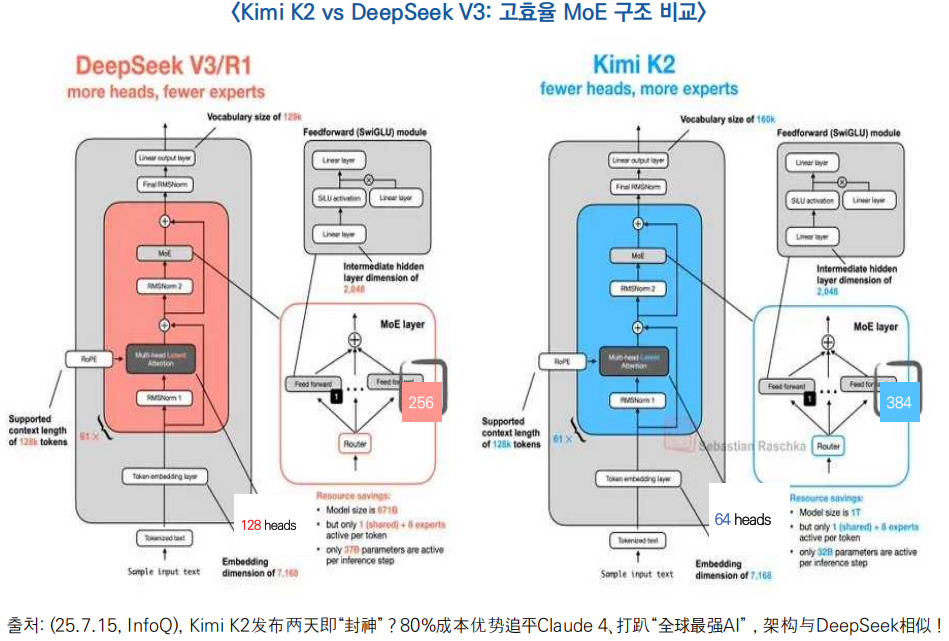
 ○ (DeepSeek와 비교) Kimi K2와 DeepSeek V3는 모두 MoE(Mixture of Experts)* 훈합 전문가 구조 기반의 LLM 모델로, 전체 구조는 유사하지만 세부 설계가 다름
* 기존 모델(일반 트랜스포머): 한 명의 셰프가 모든 요리를 다 만들어야 합니다. 피자, 스테이크, 디저트까지 전부 맡기 때문에 시간이 오래 걸리고 효율이 낮음→ MoE 모델: 피자는 피자 전문가, 스테이크는 스테이크 전문가, 디저트는 디저트 전문가가 각각 맡아서 조리합니다. 이렇게 필요할 때만 해당 전문가를 호출하기 때문에 더 빠르고, 더 나은 품질의 결과를 제공
- Kimi K2는 Multi-Head Attention 수가 64개, 전문가 수가(MOE) 384개로 구성되어 있으며, DeepSeek V3(128개, 256개)보다 연산 효율이 높음**
** Head 수가 줄면 문맥 이해가 떨어지지만, MoE는 하나의 공간 안에서 여러 전문가가 역할을 나눠 처리해 더 정밀하고 효율적인 결과를 낼 수 있습니다.
 □ 시사점
○ Moonshot AI 등 유니콘 스타트업들이 상용 모델 수준의 오픈소스 기술로 빠르게 부상하면서, 중국은 2025년 상반기에만 300개 이상의 LLM을 출시할 정도로 국내 경쟁이 치열
○ 한편, AI의 품질, 윤리, 신뢰성, 데이터 보안 등 향후 해결해야 할 새로운 과제로 부상
<참고자료>
(25.7.15, InfoQ) Kimi K2发布两天即“封神”?80%成本优势追平Claude 4、打趴“全球最强AI”,架构与DeepSeek相似!
(25.4.8, CIW NEWS) China AI startups lead global patent race
작성자: 정리 연구원(miouly@naver.com)
|
SEARCH
- 정책동향
- 이슈리포트
- 통계DB
- 통계DB