| 10배 압축에도 정확도 97%… 딥시크 ‘DeepSeek OCR’이 만든 AI 인식 혁명 | ||
|
||
|
□ 중국 AI 기업 딥시크(DeepSeek)가 혁신적인 모델 ‘DeepSeek OCR(광학 문자 인식)’을 공개(25.10.21)
○ (개요) DeepSeek OCR은 긴 문서를 효율적으로 처리하기 위해 텍스트를 ‘그림처럼 읽는’ 방식을 도입했으며, 기존 모델 대비 훨씬 적은 연산자원으로 대규모 문서를 빠르게 분석할 수 있음
- 기존 대형언어모델이 글자를 ‘토큰(token)’ 단위로 인식하는 것과 달리, DeepSeek OCR은 텍스트를 이미지로 변환해 동일한 정보를 표현함으로써 약 10배 수준의 데이터 압축을 달성
- 연구진은 문서 인식 벤치마크 ‘폭스(Fox)’ 데이터셋을 통해 DeepSeek-OCR을 검증한 결과, 10배 압축에서도 약 97%의 정확도를 유지하며, 20배 압축 시에도 60% 수준의 성능을 보임
- ‘옴니독벤치(OmniDocBench)’ 평가에서, 페이지당 256개 토큰을 사용하는 ‘GOT-OCR 2.0’을 100개의 비전 토큰만으로 능가했으며, 평균 6000개 이상 토큰을 사용하는 ‘MinerU 2.0’ 대비 800개 미만의 토큰으로 더 높은 성능을 달성
 ○ (구성) DeepSeek OCR 모델은 인코더 역할을 하는 ‘딥인코더(DeepEncoder)’와 디코더 역할을 하는 ‘DeepSeek-3B-MoE-A570M’ 2가지 아키텍처로 구성
1) 시각 인코더: 딥인코더(DeepEncoder)
- 약 3억8000만개*의 매개변수를 가진 딥인코더는 메타의 SAM(Segment Anything Model)과 오픈AI의 CLIP을 결합한 것으로, 이를 통해 세부 정보와 전체 문맥을 동시에 이해하는 시각 인식 능력을 갖춤
* SAM-base 8000만 개 매개변수, CLIP-large 3억 개 매개변수
- 핵심은 두 모델 사이에 16배 압축기가 이미지 토큰 수를 대폭 줄일 수 있으며 예를 들면 4096개 토큰이 소요되던 1024x1024 픽셀 이미지를 단 256개 토큰으로 압축 가능
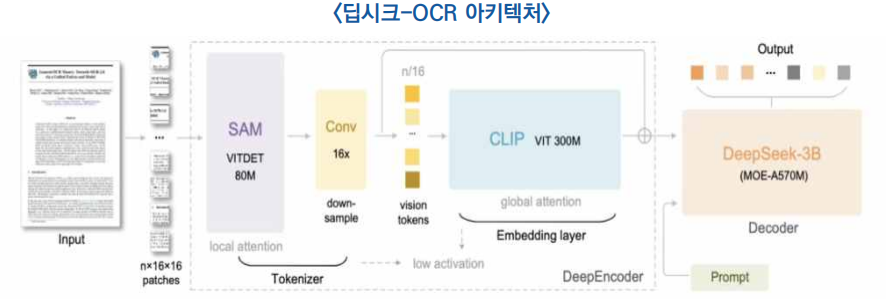 2) 텍스트 복원 디코더: DeepSeek-3B-MoE
- DeepSeek-3B-MoE-A570M은 약 3억 개의 활성 매개변수를 가진 전문가 혼합(MoE) 구조의 언어 디코더로, 이미지 입력으로부터 텍스트의 의미를 정밀하게 재구성
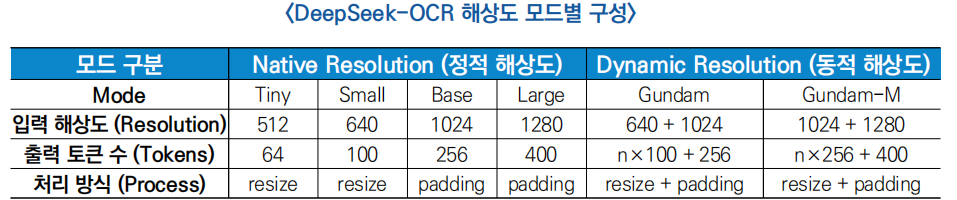
 ○ (다양한 해상도 모드) DeepSeek OCR은 이미지 해상도에 따라 64~400개 시각 토큰만으로 문서를 표현할 수 있으며, 이는 기존 OCR 시스템의 수천 개 토큰 대비 현저히 효율적임
- 딥인코더(DeepEncoder)는 ① 정적 모드 ② 동적 모드 총 2가지 작동 모드를 지원하며 문서 복잡도에 따라 토큰 수를 유연하게 조절할 수 있어, 개발자가 성능–비용 간 최적 균형을 설정할 수 있는 장점을 보유
 <참고자료>
(25.10.21, CSDN) DeepSeek新模型“杀疯了”!用视觉压缩文字,开源即获5.7k Star,Karpathy直呼:Tokenizer必须被淘汰
(25.10.21, 量子位) DeepSeek新模型被硅谷夸疯了!
작성자: 우만주 연구원(yumanshu@kostec.re.kr)
|
SEARCH
- 정책동향
- 이슈리포트
- 통계DB
- 통계DB