| DeepSeek의 등장으로 촉발된 AI의 새로운 혁신 패러다임 | ||
|
||
|
□ 중국 정부는 인공지능 산업의 지속적인 성장을 위해 다양한 지원 정책을 추진하고 있으며, 이에 따라 DeepSeek을 비롯한 AI 대규모 모델 시장이 빠르게 확대되고 있음
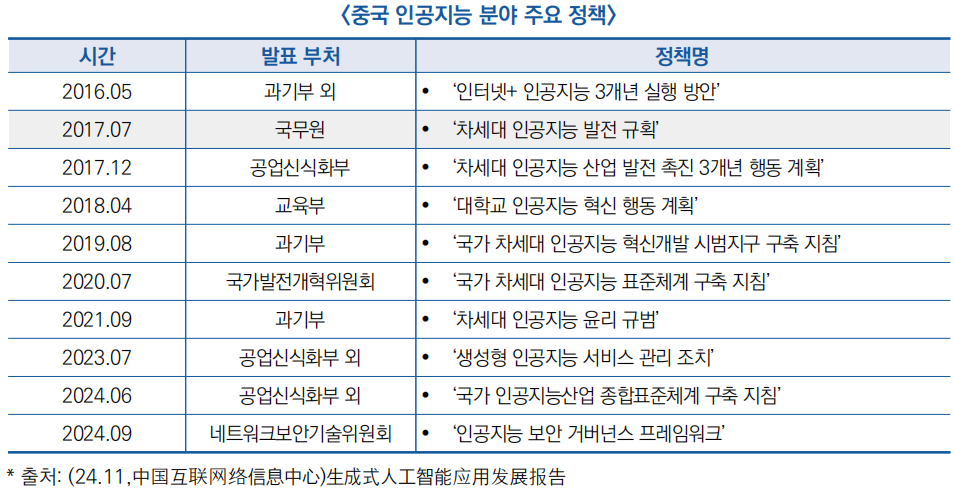
○ (정책) 중국 정부는 ′16~′20년 AI 관련 정책을 주로 발전 계획 수립과 인재 양성에 초점을 맞췄으나, ′20년 이후, 특히 ′23년부터는 표준화 체계 구축과 산업 규범 정비에 중점을 두고 있음
 ○ (투자) ′24년 1~3분기 동안 중국에서 발생한 AI 관련 투자 및 금융 조달 건수는 총 504건이며, 투자 금액은 약 812억 위안(약 16조 970억 8,800만 원)에 달함
- AI 자체 응용과 전통 산업 응용이 각각 27.4%(138건)로 가장 큰 비중을 차지했으며, 로봇 관련 분야가 23.6%(119건), AI 하드웨어와 기술은 15.7%(79건)를 기록
○ (산업) 중국은 4,500개 이상의 AI 관련 기업과 약 6,000억 위안에 이르는 핵심 산업 규모를 보유
- ′24년 상반기 기준, AI 기업 수는 전년 대비 35.65% 증가했으며, 생성형 AI 대규모 모델은 190개 이상이 등록·운영 중임
○ (제품) ′24년 6월 기준, 중국의 생성형 AI 제품 사용자 수는 약 2.3억 명으로 전체 인구의 16.4%를 차지
- 바이두의 운신이옌(文心一言), 360의 즈나우(智腦) 등 중국산 생성형 AI 제품은 사용자층에서 광범위하게 활용되고 있으며, OpenAI와 구글 등 해외 기업의 제품 또한 일정한 사용자를 확보하고 있음
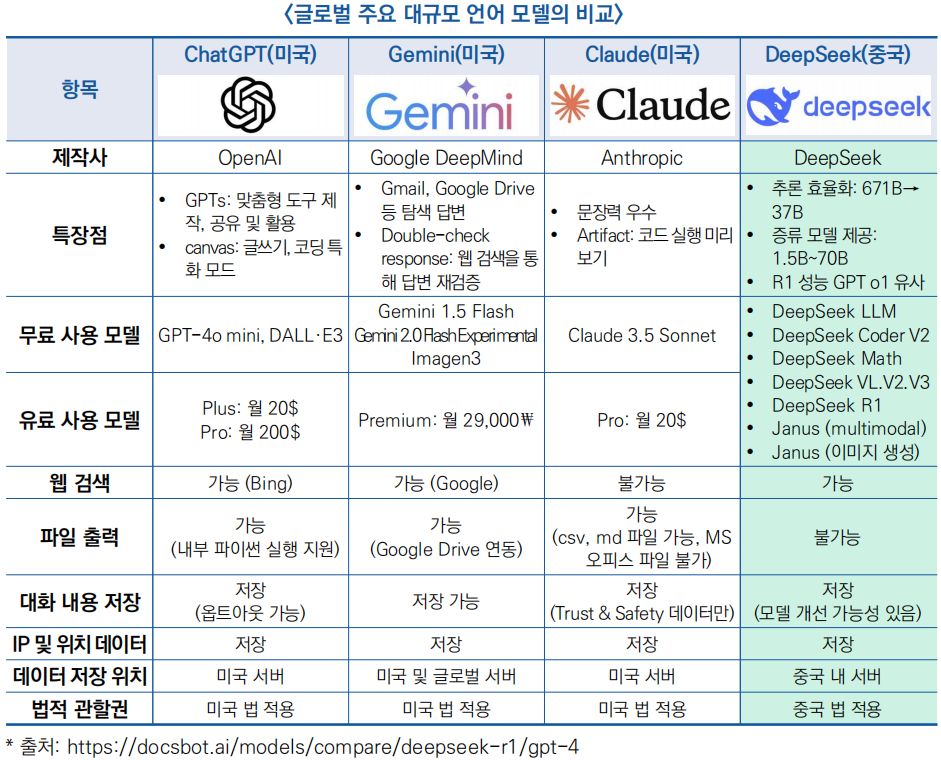
□ DeepSeek-R1은 ′25년 1월 중국 AI 스타트업 DeepSeek가 출시한 대규모 언어 모델(LLM)로, OpenAI, Google 등과 경쟁할 수 있는 오픈소스 AI를 목표로 개발됨
1. DeepSeek의 설립
○ DeepSeek는 중국 헤지펀드 High-Flyer의 범용인공지능(AGI) 연구 조직으로 출범했으며, ′23년 7월 독립 법인으로 분사되었음
* DeepSeek 창립자인 량원펑(梁文锋)은 ′15년에 설립된 퀀트 헤지펀드 회사인 High-Flyer(幻方量化)를 창립하였으며, AI 기술을 투자 거래에 적용하는 데 주력해 왔음
○ High-Flyer는 금융 데이터 분석 및 알고리즘 최적화 분야에서 축적된 경험을 바탕으로 DeepSeek의 AI 모델 개발을 적극 지원하고 있으며, 이를 통해 DeepSeek는 단기간 내 빠른 성장을 이루고 있음
 2. DeepSeek의 혁신과 성장 (DeepSeek-R1 출시)
○ (혁신을 통한 급성장) DeepSeek는 설립 후 2년이 채 되지 않은 짧은 기간 동안 오픈소스 AI 모델과 대형 언어 모델을 연속적으로 출시하며 비용과 성능면에서 혁신을 달성하며 성장
- 가격 및 접근성 : R1은 MIT 라이선스 기반의 오픈소스로 무료제공되며, OpenAI GPT-4 및 Google Gemini와 같은 폐쇄형 모델 대비 기업 맞춤형 활용이 가능하도록 혁신
- 컨텍스트 길이 : 128K 토큰 지원으로 GPT-4(32K) 대비 4배 긴 문맥을 처리 가능, Google Gemini Flash Thinking(1M)보다 짧지만 실용적인 성능을 보장하며 혁신
 ○ (젊은 인재의 확보) DeepSeek의 R&D 인력은 총 139명으로, 대부분 칭화대, 베이징대 등 중국 최고 대학 출신의 20~30대 젊은 인재들로 구성되어 있음
 ○ (돌파형 기술 혁신) DeepSeek-R1은 MLA, 전문가 혼합(MoE) 기반 트랜스포머 모델과 강화 학습(RL) 중심의 미세 조정 기법을 적용하여 효율적인 연산과 향상된 논리적 사고 능력을 구현
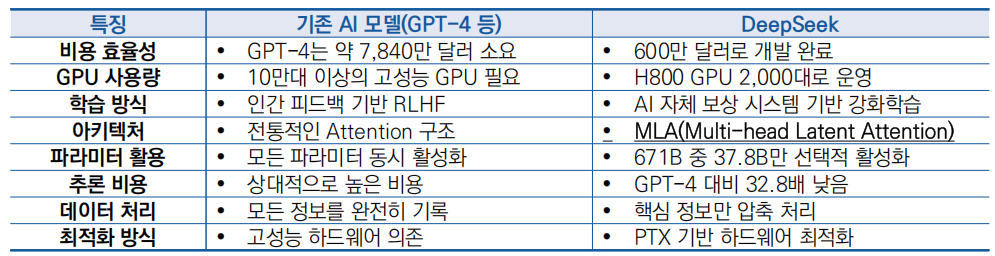 - MLA(Multi-head Latent Attention) 혁신 : 기존 AI 모델은 마치 회의 내용을 전부 다 받아적는 비서와 같이 회의 참석자들의 모든 말, 소소한 대화, 심지어 쓸모없는 잡담까지 모두 기록하는데, 이렇게 하면 시간이 오래 걸리고, 리소스가 많이 소요되는 문제가 발생했지만, MLA는 마치 핵심만 요약해서 기록하는 똑똑한 비서와 같이 대화의 중요한 포인트만 정리하고 압축하고 불필요한 세부 정보는 무시하여 빠르고 정확한 판단을 할 수 있게 지원하는 기술
- 전문가 혼합(MoE, Mixture of Experts) 혁신 : OpenAI GPT-4 및 O3는 밀집(dense) 모델 구조를 사용하는 반면에, DeepSeek-R1은 전문가 혼합(MoE) 기반 트랜스포머 모델로, 전체 6710억 개의 매개변수 중 토큰당 약 370억 개만 활성화됨
* 기존 모델(일반 트랜스포머): 한 명의 셰프가 모든 요리를 다 만들어야 합니다. 피자, 스테이크, 디저트까지 전부 맡기 때문에 시간이 오래 걸리고 효율이 낮음
* MoE 모델: 피자는 피자 전문가, 스테이크는 스테이크 전문가, 디저트는 디저트 전문가가 각각 맡아서 조리합니다. 이렇게 필요할 때만 해당 전문가를 호출하기 때문에 더 빠르고, 더 나은 품질의 결과를 제공
- 강화학습 기반의 혁신 : DeepSeek는 기존의 모범 답안을 보고 배우는 지도 학습(SFT: Supervised Fine-Tuning) 대신 스스로 여러 가지 시도를 통해 정답을 찾는 강화 학습(RL: Reinforcement Learning) 중심의 미세 조정을 적용하여 모델의 논리적 사고 능력을 향상
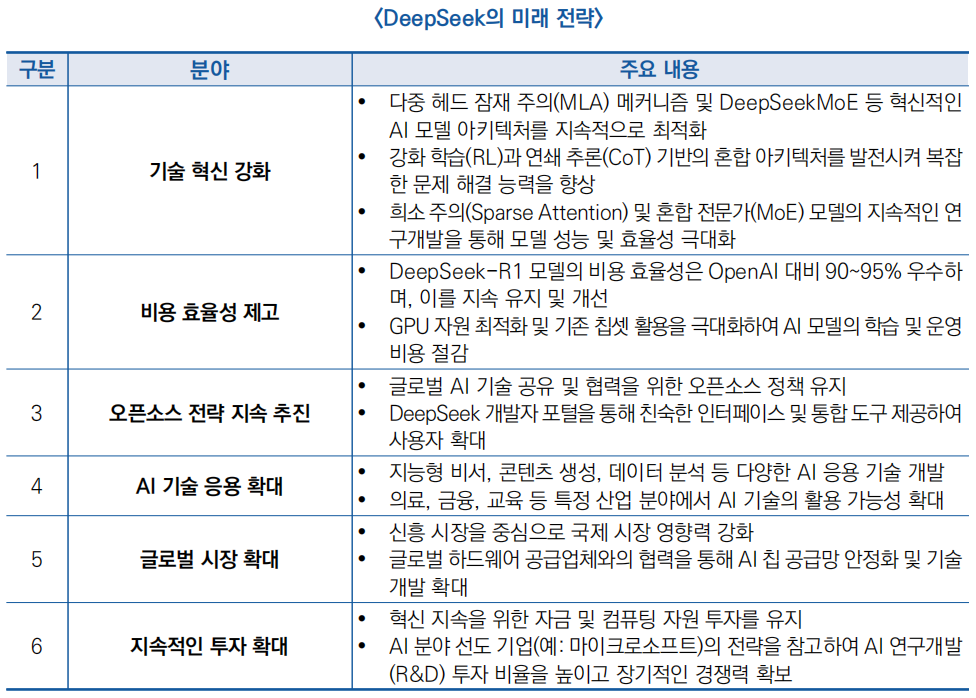
 3. DeepSeek의 미래 전략
○DeepSeek은 기술 혁신, 비용 효율성 강화, 오픈소스 전략, 글로벌 시장 진출 및 지속적인 투자를 핵심 전략으로 삼고 있으며, 이를 통해 AI 기술의 발전과 산업 내 경쟁력을 지속적으로 강화할 전망
 <참고자료>
(25.2.2,腾讯网) 一文看懂DeepSeek的中国式创新
(25.2.3,新浪财经) 传奇背后:DeepSeek创始人梁文锋的创新认知
(25.2.6,中国银河证券) 2025年科技行业专题报告:DeepSeek,技术颠覆or创新共赢
(25.2.3,新浪财经) DeepSeek最强专业拆解来了,清交复教授超硬核解读
(25.1.7,3D快报) 杭州DeepSeek公司挑战全球巨头,成为AI大模型革新先锋
(25.5.10,经济网) DeepSeek改变AI未来——最应该关注的十大走向
작성자: 정리 연구원(miouly@naver.com)
|
SEARCH
- 정책동향
- 이슈리포트
- 통계DB
- 통계DB