| 딥시크, 최신 AI 모델 ‘V3.2’로 글로벌 경쟁 가속…구글 제미나이3 정면 도전 | ||
|
||
|
□ 중국 생성형 인공지능(AI) 기업 딥시크(DeepSeek)가 12월 1일 최신 모델 ‘딥시크 V3.2’와 고연산 특화 버전 ‘V3.2-스페치알레(Speciale)’를 공개
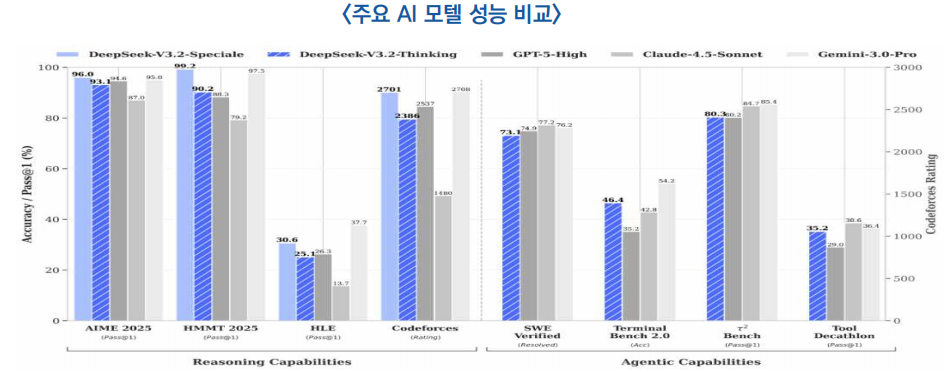
○ (성능 비교) 이번 DeepSeek-V3.2 시리즈는 추론·지능형 에이전트 등 주요 벤치마크 전반에서 세계 오픈 소스 모델 중 최고 수준의 성능 기록
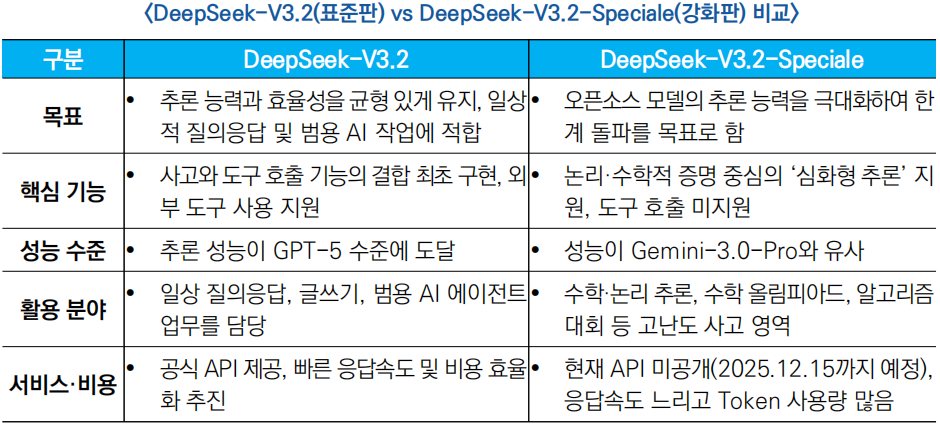
- DeepSeek-V3.2는 일상적 활용에 최적화된 모델로, 공개 추론 테스트에서 GPT-5 수준에 도달했으며 구글의 제미나이 3.0 Pro보다 약간 낮은 성능을 보유
- DeepSeek-V3.2-Speciale는 명령 수행, 수학적 증명, 논리 검증능력이 뛰어나며, 주요 추론 벤치마크에서 Gemini-3.0-Pro와 대등한 수준의 성능을 보임
  ○ (기술 혁신) 이번 DeepSeek-V3.2 시리즈는 대형 언어 모델 아키텍처 구조와 훈련 방식 모두에서 뚜렷한 기술적 돌파구를 제시
1) 희소 어텐션(sparse attention)*
* 희소 어텐션: 인공지능이 모든 문장을 다 보지 않고, 핵심 단어와 문장만 선택적으로 집중하도록 만든 기술
- 희소 어텐션 시스템은 ‘라이트닝 인덱서(번개 색인기)’와 ‘세밀한 토큰 선택 시스템’을 함께 사용해, 긴 문장이나 글에서 중요한 부분만 선택적으로 분석하는 방식임
2) ‘추론 능력’와 ‘도구 활용’의 결합
- 기존 AI 모델들이 연산이나 검색 등 외부 도구를 사용할 때 단순한 명령어 처리에 그쳤다면, V3.2는 인간과 유사한 추론 과정을 거쳐 검색엔진, 계산기, 코드 실행기(Code Executor) 등의 도구를 자율적으로 활용
3) 고도화된 훈련 방식
- 복잡한 문제 해결 능력을 높이기 위해 전문가 지식 전달(전문가가 AI에 지식을 가르치는 방식)과 강화학습(스스로 시행착오를 통해 배우는 방식)을 결합하여 학습 효율을 향상
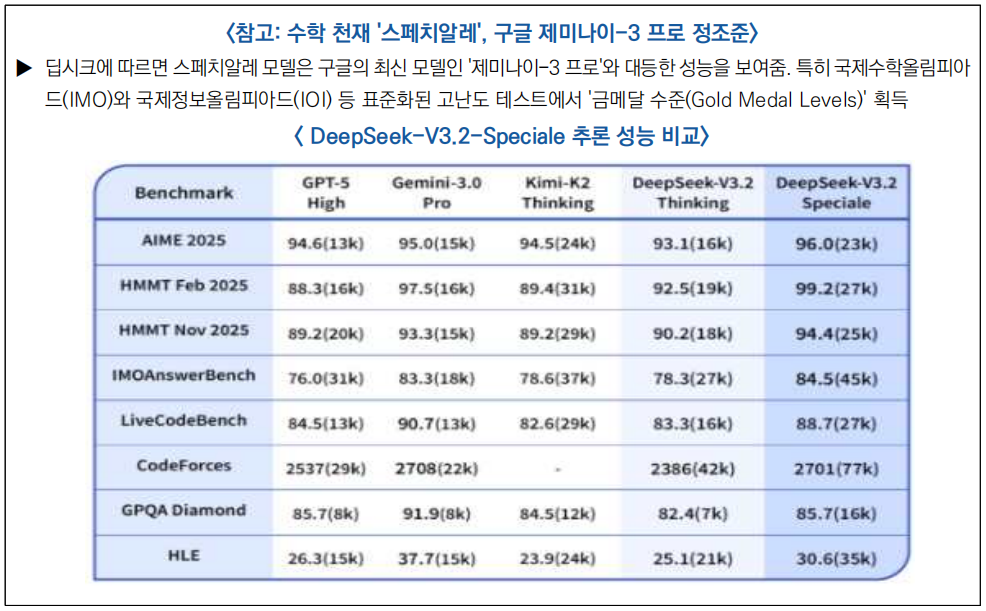 ○ (한계 및 개선 방향) DeepSeek- V3.2 시리즈는 오픈소스 모델 중 최고 수준의 추론 성능을 보여주었지만, 여전히 폐쇄형 초거대 모델(Gemini-3.0-Pro 등)과 비교할 때 몇 가지 구조적 한계가 존재
1) 학습 연산량의 한계
- DeepSeek-V3.2는 훈련 연산량(FLOPs, 부동소수점 연산 규모)이 상대적으로 적어, 세계 지식과 일반 상식의 폭이 여전히 선도적인 폐쇄형 모델에 비해 제한적임
* 차세대 버전에서 사전 학습(Pre-training)에 투입되는 연산 규모를 대폭 늘려, 이러한 지식의 격차를 메워 나갈 계획
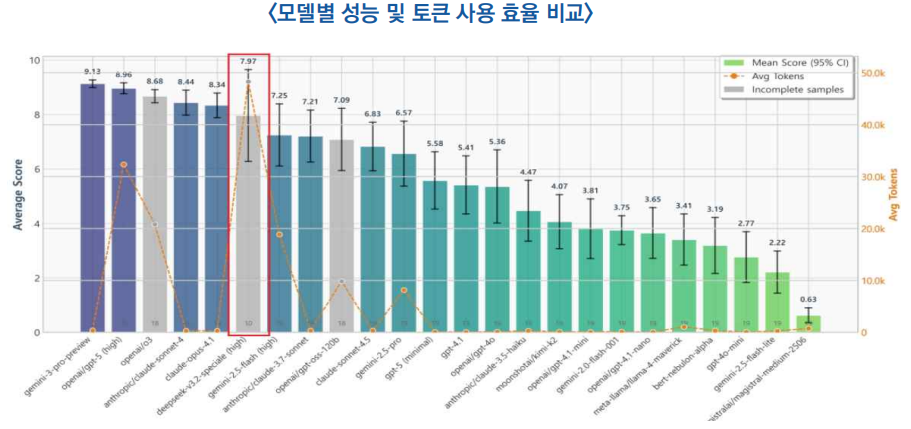
2) 토큰 효율성 저하
- DeepSeek-V3.2는 Gemini-3.0-Pro와 동일한 수준의 성능을 내기 위해 경쟁 모델보다 더 많은 토큰을 소모하는 비효율적 구조를 보임
* 구글의 제미나이(Gemini)는 2만 개 토큰만 사용하지만, 딥시크 스페치알레(Speciale)는 약 7.7만 개를 소모함
 3) 복잡한 과제 해결 능력 부족
- DeepSeek-V3.2는 복잡한 문제를 해결하는 데 아직 최첨단 모델 수준에 미치지 못하며, 이를 개선하기 위해 기반 모델(Foundation model)과 사후 학습(Post-training) 방식을 정교하게 다듬을 필요가 있음
<참고자료>
(25.12.2, 智东西) 梁文锋署名论文,DeepSeek最强开源Agent模型炸场
(25.12.3, 河口智算中心) DeepSeek重磅发布的V3.2 和 V3.2-Speciale详解
(25.12.1, DeepSeek) DeepSeek V3.2 正式版:强化 Agent 能力,融入思考推理
(25.12.4, 量子位) DeepSeek-V3.2被找出bug了:疯狂消耗token,答案还可能出错,研究人员:GRPO老问题没解决https://h5.ifeng.com/c/vivoArticle/v0029rrJk--8xKs--c7ocEyfImLbCX8Rkyu3O63QEl9DQKW8k__
작성자: 우만주 연구원(yumanshu@kostec.re.kr)
|
SEARCH
- 정책동향
- 이슈리포트
- 통계DB
- 통계DB